Cherry Studio:开源AI客户端,使用DeepSeek提升效率神器介绍一下Cherry Studio的相关使用。Cherry Studio的介绍Cherry Studio是一个开源的支持多模型服务的桌面AI客户端,为专业用户而打造。集成了超过 300 多个大语言模型,内置 30 多个行业的智能助手,帮助用户在多种场景下提升工作效率。支持macOS、Windows、Linux。提供了丰富的功能,如:对话、智能体、绘画、翻译、知识库等功能在Cherry Studio中使用硅基流动Cherr
Cherry Studio:开源AI客户端,通过第三方客户端的方式来使用DeepSeek。来解决DeepSeek官方经常出现的“服务器繁忙”的问题。 但是还是存在两个问题需要解决:客户端只能在Mac、Windows、Linux上用,手机使用不方便还不支持联网搜索功能。在Ollama本地模型部署社区工具中Open WebUI是一个开源浏览器前端界面项目,支持联网搜索。我们可以通过它来使用DeepSeek的的联网功能。Open WebUI 是什么?Open WebUI 是一个开源的、可扩展、功能丰富

开源!基于DeepSeek的本地化企业内部知识库和工作流平台, 允许商业化源代码http://www.gitpp.com/sciences/deepseek-localweb-ragDeepSeek本地知识管理平台:全面、安全、高效的智能解决方案在当前数字化和信息化的浪潮中,企业和机构对于高效、安全的知识管理和智能服务需求日益增长。DeepSeek本地知识管理平台应运而生,它基于DeepSeek这一开源且性能卓越的大模型,旨在为企业和机构提供一套功能全面、安全高效的智能解决方案。一、文档智能功能
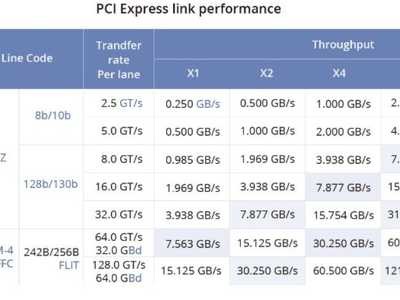
0x01 传统Pcie与NVLink1. PCIe(Peripheral Component Interconnect Express):它是一种计算机总线标准,用于在计算机内部连接各种设备和组件(例如显卡、存储设备、扩展卡等)。PCIe接口以串行方式传输数据,具有较高的通信带宽,适用于连接各种设备。然而,由于其基于总线结构,同时连接多个设备时可能会受到带宽的限制。2. NVLink(Nvidia Link):它是由NVIDIA开发的一种高速、低延迟的专有连接技术,主要用于连接NVIDIA图形处

在人工智能和大型语言模型(LLMs)领域,Ollama作为一款专注于简化大型语言模型在本地部署和运行的开源框架,受到了广泛关注。然而,Ollama并非唯一的选择,市场上还有许多其他同类型的工具,为开发者提供了多样化的选项。本文将盘点与Ollama同类型的大模型框架工具,帮助用户更好地了解这一领域的技术生态。一、Ollama框架简介Ollama是一个专注于简化大型语言模型(LLM)在本地部署和运行的开源框架。它支持多种大型语言模型,如Llama 2、Code Llama、Mistral、Gemma
Ollma和vLLM简单对比AI应用开发中最常见两个大模型推理框架Ollama和vLLM. 在应用开发过程中,开发者通常会从多方面进行比较来选定适合的推理框架,尤其是在对接本地大模型时,考虑因素包括本地资源配置,本地安全性要求,成本计算,响应要求等多个方面。下面针对这两个常见框架,做一个简要的对比:Ollama1. 说明:Ollama是一个开源的大模型服务工具,可以让你在不写代码的情况下,在本地通过命令运行需要的大模型。Ollama会根据用户的资源配置,自动选择GPU或CPU运行,运行速度取决于

这两年是大模型盛行的黄金时代,各大优秀的大模型诸如GPT、LLM、QWen、Deepseek等层出不穷,不断刷新我们的认知;但是大模型都有一个共同的特点,都拥有非常惊人的参数量,小的都有上十亿的参数,大的更是可以有几千亿的参数,这么大的参数量就会带来一个新的问题,就是推理效率不如传统的深度学习模型,再有就是目前的大模型基本上都是基于transformer进行开发的,最大限制上下文token数会导致模型在显存的利用率上会有很大的缺陷,基于此,专

vLLM 专为高效部署大规模语言模型设计,尤其适合高并发推理场景,关于对vLLM的介绍请看这篇博文。以下从 安装配置、基础推理、高级功能、服务化部署 到 多模态扩展 逐步讲解。 1. 环境安装与配置1.1 硬件要求GPU: 支持 CUDA 11.8 及以上(推荐 NVIDIA A100/H100,RTX 4090 等消费级卡需注意显存限制)显存: 至少 20GB(运行 7B 模型),推荐 40
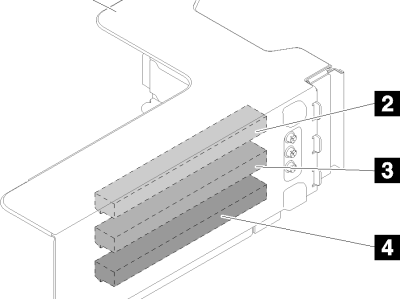
https://pubs.lenovo.com/sr860/zh-CN/pcie_riser_cardPCIe 转接卡按以下信息查找可选 PCIe 转接卡上的接口。x8/x8/x8 PCIe FH 转接卡组合件图 1. x8/x8/x8 PCIe FH 转接卡组合件表 1. x8/x8/x8 PCIe FH 转接卡组合件的组件1 PCIe 全高型转接卡架3 PCI Express 3.0 x8(插槽 6)2 PCI Express 3.0 x8(
随着人工智能和图形处理需求的不断增长,多 GPU 并行计算已成为一种趋势。对于多 GPU 系统而言,一个关键的挑战是如何实现 GPU 之间的高速数据传输和协同工作。然而,传统的 PCIe 总线由于带宽限制和延迟问题,已无法满足 GPU 之间通信的需求。为了解决这个问题,NVIDIA 于 2018 年推出了 NVLINK,以提高 GPU 之间的通信效率。了解 NVLINKNVLINK 是一种专门设计用于连接 NVIDIA GPU 的高速互联技术。它允许 GPU 之间以点对点方式进行通信,绕过传统的
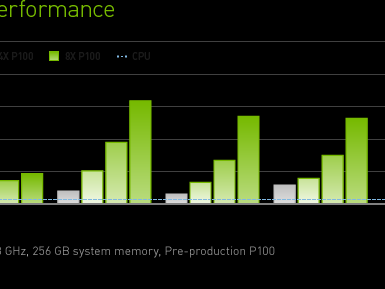
https://www.nvidia.cn/data-center/tesla-p100/NVIDIA Tesla P100世界首款 AI 超级计算数据中心 GPU超强计算能力助力现代数据中心当今的数据中心有赖于大量互连的通用计算节点,这限制了高性能计算 (HPC) 和超大规模工作负载。NVIDIA® Tesla® P100 运用 NVIDIA Pascal™ GPU 架构提供统一的平台,以加速 HPC 和 AI 发展,大幅提升吞吐量,同时降低成本。应用程
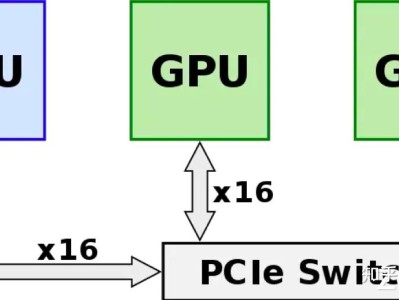
随着 AI 技术的飞速发展,大模型的参数量已经从亿级跃升至万亿级,这一变化不仅标志着 AI 的显著提升,也对支持这些庞大模型训练的底层硬件和网络架构提出了前所未有的挑战。为了有效地训练这些复杂的模型,需要依赖于大规模的 GPU 服务器集群,它们通过高速网络相互连接,以便进行快速、高效的数据交换。但是,即便是最先进的 GPU 也可能因为网络瓶颈而无法充分发挥其计算潜力,导致整个算力集群的性能大打折扣。这一现象凸显了在构建大规模 GPU 集群时,仅仅增加 GPU 数量并不能线性增加集群的总体算力。相