写文时间:2025年2月15日。一切价格与性价比相关信息以此时为准。
deepseek爆火的背后,溯其本源,是这两个关键句:大公无私的开源精神;打破常规的低成本。我们夸它开源,是因为它媲美全球各大公司的闭源模型;我们夸它成本低,绝不是夸它“用的钱少”,不是所谓“仅几百万美金的训练成本”,而是背后研究团队对MoE架构的改良、对注意力机制的改进、对迭代算法的各种优化……研究团队没有一味地砸钱炼丹,而是直接大步迈向“高效率”这个方向。也正是借助此契机,人们方开始转头探索大模型部署成本下限。
言(屁)归(话)正(少)传(说),大家讨论“本地推理满血r1”的声音越来越大,可能已成很多人的梦想甚至小目标了。我归纳整合了一些主流的部署方案,包括很多新奇思路,先不讨论“算力”,先说本地部署总共要花费的“钱力”区间吧:低至2.7万元,高达150万元+。
最最原始的模型使用BF16作为推理精度,这是绝对的真·满血,然而这个炼丹炉里的母体对于我们部署起来实在太为艰难,因此我们只考虑量化版本。
6710亿(671B)参数量、INT8量化的R1通常被大家称为“满血”版R1,因为从16位量化到8位这个过程是公认为性能损失最小的量化。实际上,往下的70B、32B、14B等小模型都只能算得上是“旁系亲属”,它们是从通义千问/llama两个老牌模型中融合蒸馏得来的“混血deepseek”,更算不上满血,因此也不作讨论。
先了解deepseek R1 671B模型究竟有哪些主流量化版本:
1.纯正血统の完全体:基于INT8的、710G大小的原版模型(在http://huggingface.co上能下载到)
2.亲儿子:INT4版本的R1,经过INT8量化得到,体积小了近1半,也是Ollama上能下载到的最强R1
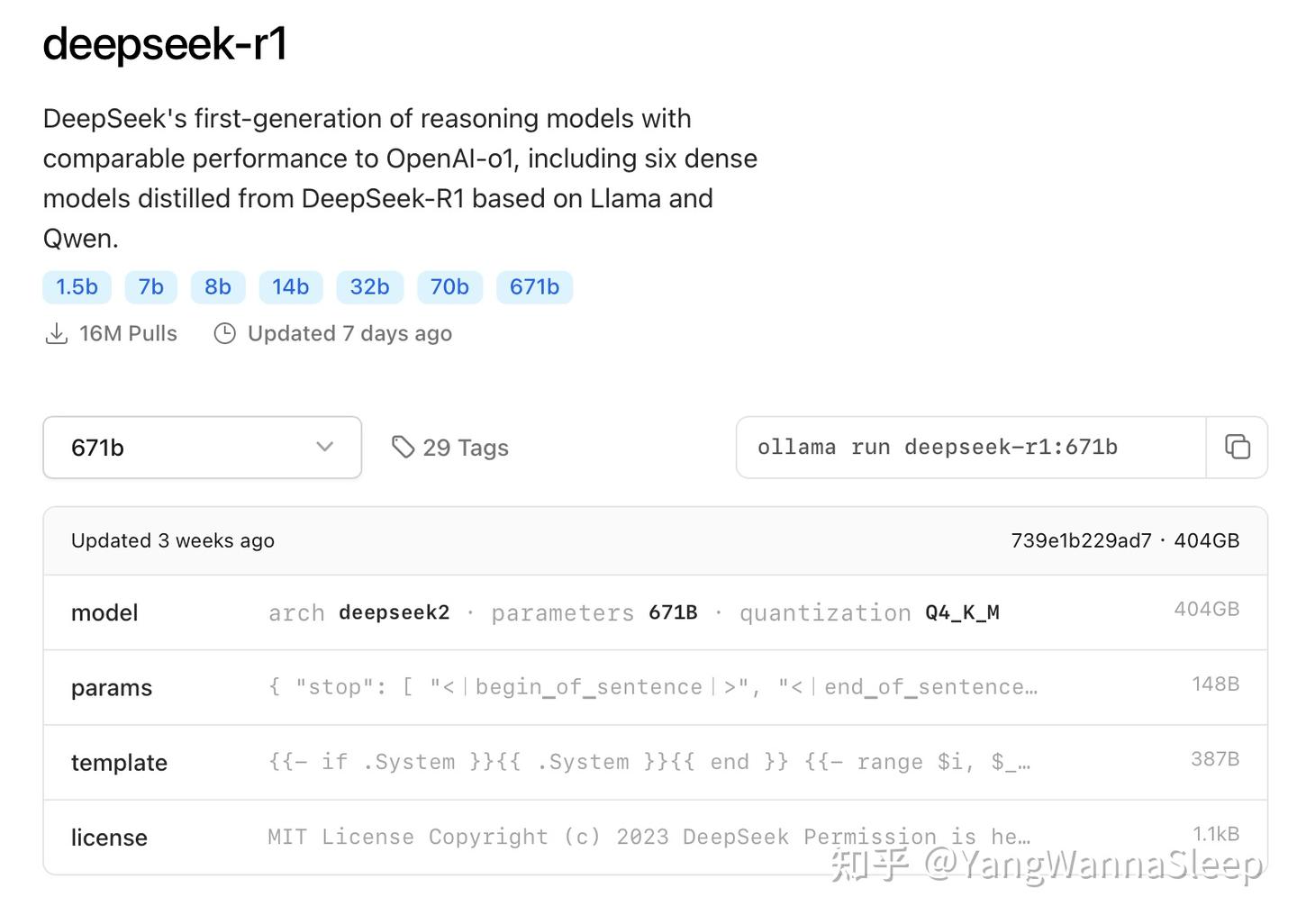
3.直系亲属:各种究极量化瘦身版本,基本上都是传奇量化王Unsloth AI的杰作,旨在进一步缩减内存需量,能力相对较弱一些

这四个Unsloth量化版本使用了动态范围量化算法,其中最小的1.58bit MoE量化版本应该是目前对硬件要求最低的R1版本,量化体积已经来到了IQ1_S,不过性能非常弱鸡,可能甚至不如Q8的70b蒸馏模型。我仅推荐其中的2.51bit即Q2_K_XL版本。
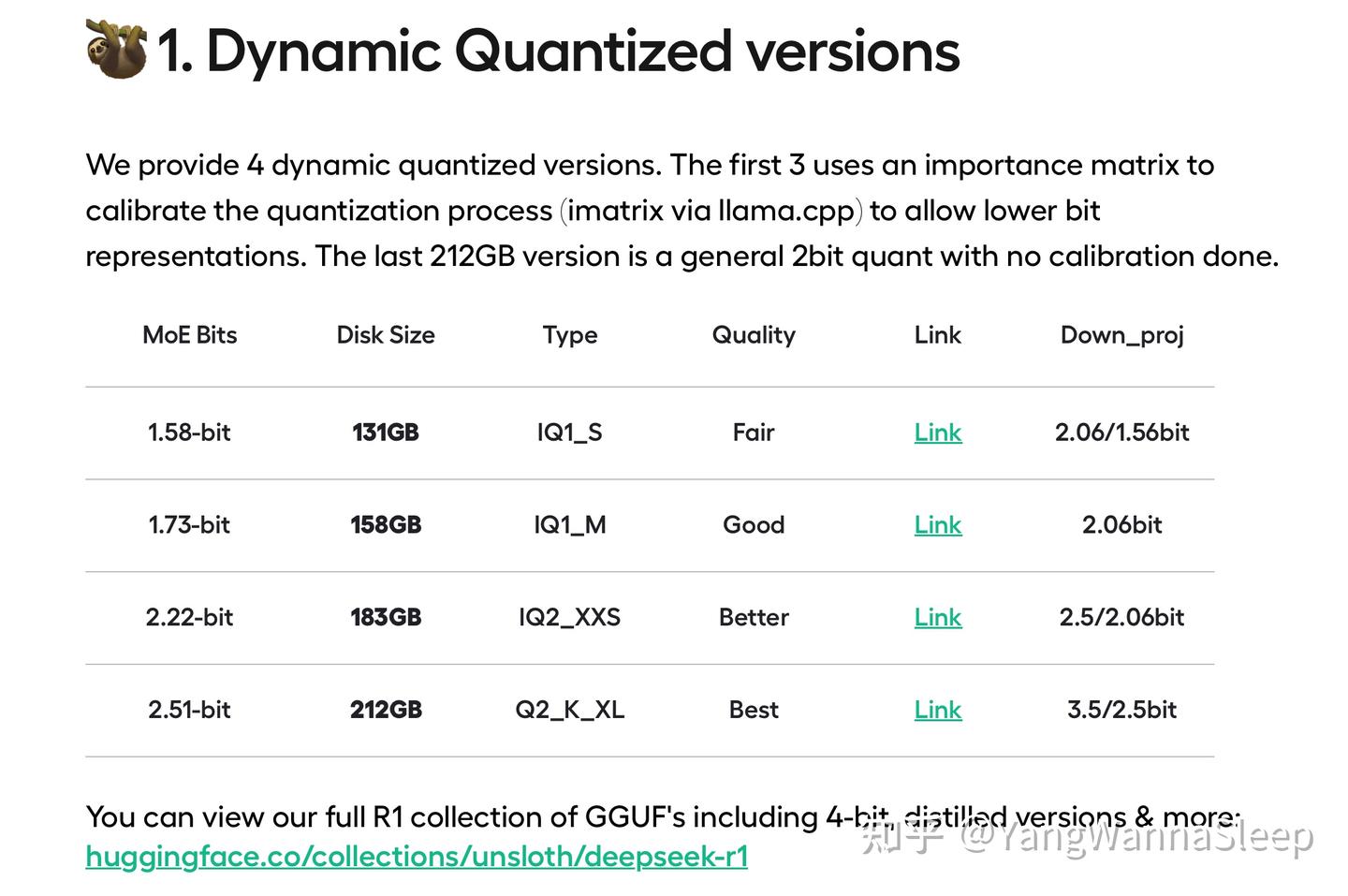
本文将只讨论Q8、Q4和2.51bit瘦身版(以下简称Q2版)的R1。
0、硬性内存需求
部署大模型的硬性要求是内存,内存容量决定能不能跑,内存带宽和处理器决定I/O速度,理论上只要有足够大的内存,什么配置的现代计算机都能跑动大模型。
根据各方实测,Q8版本的R1在32K上下文窗口下的推理要占用730~750G的内存;
Q4版本需要至少360G~370G的内存;
Q2版本则需要250G左右的内存。
1、企业级部署/富哥部署方案(仅Q8)(全能战士)
多GPU集群部署、尤其是专业GPU部署大模型会产生很多性能冗余,所以大规模的GPU集群一般面向对外服务业务,即一套系统同时部署多份实例,以充分利用强大的算力。
这个档次下,将模型全部加载在GPU内存即显存(VRAM)中可获得最高性能和效率。
最主流的多卡A100 80G、H100 80G集群就是最高档的选择,这种顶尖GPU已经算不上“图形处理单元”了,严谨一些该称为GPGPU,“通用计算”图形处理单元,强调计算。1台8卡服务器就能提供640G的VRAM,并具备上万甚至十万多TOPS INT8的算力总成,一般可以支持50~100个实例同时部署,也就是一台机器同时服务几十个客户。
比如超微的420GP服务器,搭载NVIDIA HGX系统8卡A100服务器,八个GPU直接封装在一张电路板上,实现卡间高带宽低延迟的通信。一台价格高达150万+。

另提一嘴,这种最顶尖的GPGPU支持的精度格式非常多(FP8、INT4/8、FP16/BF16、FP32/TF32、FP64等),不仅适用推理,也完全可以用于微调和训练,仅8卡也能提供大几千TFLOPS的FP16/BF16算力总成,只不过训练的显存需量可远大于几百G,需要多服务器集群和各种异步算法加持以保证高利用率,此不多作讨论。
2、团队高预算部署方案(可推理可微调)
顶尖GPU往下是各种高显存专业GPU,比如RTX 8000、A6000、6000 Ada或者A40/L40这种特定行业的工作站显卡。它们通常拥有消费级显卡同源同款的核心(不过在算力上大多强于消费级显卡),配备大显存,上面那几款都是48G单卡显存。
相比A100/H100,这些卡性价比高多了。一台8卡L40服务器可提供约8张4090的算力和384G的显存,一台可以完美运行Q4量化版R1,两台即可部署Q8。它们的算力也比较冗余,可以给兄弟姐妹各部署一份。
还嫌贵吗?高端局最强消费级显卡奉上:魔改4090 48G显卡。近似的性能,更高的功耗,更低的价格:

购买建议:这是此档位最具性价比的两个方案。当前A6000显卡、RTX8000等Turing/Ampere架构大显存显卡性价比较低,建议避雷。
如果想继续缩减预算,部署Q2模型,冗余考虑,可以把4090 48G减到6张,凑出288G VRAM,动手自己组装吧。购买准系统、CPU,加上6张4090 48G(某鱼价格约22000元一张),约18万~20万即可落地,建议使用双路LGA4189平台即第三代至强,许多金牌CPU价格都降到5000-一颗,PCIe通道数较前代增加,完全够用。
最后补充说明,为什么我不建议4090 24G呢?因为单卡VRAM过小仍然会制约模型性能,因为单张显卡实际可自由发挥的显存空间还是非常少。
3、个人高预算部署方案(仅推理)
在此之前,请大家了解一个非常伟大的开源项目:Ktransformers,我必须推广。就在今天,官方发布了更新日志,可前去了解:

Github链接在此,可前往查看部署教程:

可以看到Ktransformers(以下简称ktrans)正式支持了量化王Unsloth的动态量化R1 Q2模型。
这项目有什么意义呢?它实现仅几十G的VRAM即单张显卡+大容量高带宽的内存与多核CPU组合的“混动”推理形式,让平台搭建成本和推理成本都大大降低了。简单形象来说,deepseek中有许多领域的小专家,当你输入完问题,你的token激活了部分专家,这些专家起来给你回答问题。传统方案把模型一股脑加载在显存中,非常浪费GPU这个高性能高数据带宽的场合,而ktrans把那些“沉睡的专家”扔到内存中陪CPU玩,刚需的专家拉到GPU中进行加速推理。它适用诸如deepseek R1/V3这种MoE架构的LLM,对于MoE混合专家架构,具体原理比较复杂,可以看这篇非常优质详尽的文章:

ktrans还干了件事,把intel拽起来了一把:因为要涉及CPU推理,所以CPU性能必须必须强而且需要一定指令集优化,而intel的4/5代至强苦口婆心宣传的、适用AI计算的AMX指令集在此派上了用场,而ktrans团队针对AMX指令集进行了专门优化。

但这也意味着,若使用至强处理器,必须用4代可扩展及以上才能达成加速效果,否则不如选EPYC;并且内存带宽必须得很大,需要尽量插满内存插槽并尽量使用DDR5-4800+规格的较高带宽内存。事已至此,先看ktrans官方同款方案吧:
| 配件 | 型号 | 价格/元 |
|---|---|---|
| CPU | 2x Xeon Gold 6454S(ktrans官方同款,32核,支持D5-4800) | 某宝均价约7500*2=15000 |
| 主板 | 同泰怡T3DE(约等于X13DEI) | 4800 |
| 内存 | 16x SK RDIMM DDR5-4800 32G | 某宝随机店铺870*16=13920 |
| GPU | 非公版RTX 4090 24G/RTX 4090D | 某鱼二手13000~16500 |
| 硬盘 | WD SN7100 2T | 920 |
| 杂项 | 1600W巨龙电源+机箱+散热+…… | 2500 |
整套只需5.2万元,还是塔式(即台式机)服务器。此配置通过ktrans可完美部署Q4,在4K上下文的速度表现约13~15token/s(官方原文有具体表格),非常地够用。如果你想部署Q8,可增添内存至每根48G规格,大概多花5000元左右。如果你有战未来需求,也可以配一块48G大显存的专业卡,不过目前24G是完完全全够用的!
上面的配件还是太吃预算了,有没有不吃预算速度还快的配置?有的兄弟,有的,像这样的方案还有2个:(WARNING:二手配件有风险,工程样品有风险,矿渣有风险,捡垃圾有风险)
4、个人低预算部署方案(仅推理)
1.ktrans方案《改良版》
ktrans方案难道不能压榨吗?开始叠buff!
| 配件 | 型号 | 价格/元 |
|---|---|---|
| CPU | 2x Xeon Platinum 8480+ es不显版 代号QYFR/QYFS(56核,1.9/3.7) | 某鱼900*2=1800 |
| 主板 | 传奇兼容王技嘉MS73-HB1 | 6350 |
| 内存 | 16x SK RDIMM DDR5-4800 32G | 13920 |
| GPU | 前辈卡皇RTX 3090Ti 24G | 某鱼/某宝约7500~8100 |
| 硬盘 | WD SN7100 2T | 920 |
| 杂项 | …… | 2500 |
整套仅需3.4万元!也是随便跑Q2 Q4,加内存可跑Q8。肯定有人问:为什么要买矿渣至强?无所谓,内存通道齐全、有那么几条PCIe、有AVX、AMX指令集就够了。配上爱国嘉主板高兼容性的优良传统,这一套不敢说比官方方案nb,但我敢保证速度绝对在10token/s以上。
2.纯CPU推理方案
CPU推理纯粹堆核心数与内存带宽即可,于是抛弃intel转身向EPYC走去。
| 配件 | 型号 | 价格/元 |
|---|---|---|
| CPU | 1x QS大王EPYC 9654QS 编号100-000000894-04(96核,2.15/3.5) | 某鱼均价10000,怕矿可买全新约11000~11500 |
| 主板 | 超微H13SSL-N | 4650 |
| 内存 | 12x SK RDIMM DDR5-4800 48G | 某宝均价880*12=10560 |
| 硬盘 | WD SN7100 2T | 920 |
| 杂项 | 1000w电源+…… | 1500 |
整套仅需2.7万元!预测跑Q4速度可达到5~6token/s,Q2可达到7~8token/s
5、总结
对于最广大的个人用户,我强烈推荐ktrans方案,前提是满通道D5内存+多核CPU;
对于大规模企业部署,尽量回避4090 24G,控制成本完全可选4090 48G。
能花不到5万元部署600多b参数量的LLM,放在以前是想都不敢想的事。deepseek的出现,很大程度给中国甚至全球AI发展指明了新的发展路径,那就是高效。不敢说哪个性能孰强孰弱,毕竟谷歌新出的Gemini 2.0 Pro已经干掉了o3和r1/v3了,只是这一番百家竞争之势最终只会不断造福我们用户。期待我们能早日在PC上部署满血大模型!
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://sg.hqyman.cn/post/9412.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~