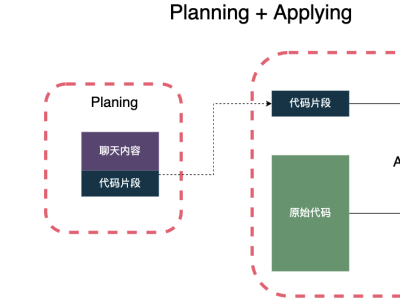
LLM生成代码后,如何一键合并到源代码中(FastApply技术研究)背景在大语言模型越来越火的今天,越来越多的应用场景开始使用大语言模型来解决实际问题。而辅助编程可以算是大语言模型应用得最成功的场景之一了。早先的时候,更多使用的还是代码补全的能力,但是现在,各家产品都开始支持Chat和Agent的能力了。之前一直有个疑问,生成的代码明明只是片段,也没有一个很好的规则能直接定位到源文件的位置,甚至有些生成的代码和现有代码没有任何重叠的部分,那这些代码是怎么精准地合并到源代码中的呢?今天就带着大家
为了改一行代码,我花了10多天时间,让性能提升了40多倍---Pascal架构GPU在vllm下的模型推理优化ChatGPT生成的文章摘要这篇博客记录了作者在家中使用Pascal显卡运行大型模型时遇到的挑战和解决方案。随着本地大型模型性能的提升,作者选择使用vllm库进行推理。然而,作者遇到了多个技术难题,需要自行编译vllm和PyTorch,以支持Pascal架构的显卡。编译过程中,作者深入研究了显卡不支持的问题,特别是在量化矩阵乘法计算中发现性能瓶颈。最终,解决了性能问题,让性能提升了43倍
大模型如何部署?目前chatgbt如火如图,但是模型参数巨大,单卡H100都无法满足,请问大模型如何部署?目标是部署类似gbt 175b参数的模型到gpu上面。硬件选型AI 领域常用 GPU显卡性能应用场景价格T4适中AI 推理, 轻量级训练, 图形渲染7999(14G)4090非常高通用计算, 图形渲染, 高端游戏, 4K/8K 视频编辑14599(24G)A10适中图形渲染, 轻量级计算18999(24G)A6000适中图形渲染, 轻量级计算32999(48G)V100高深度学习训练/推理,
作者:游凯超,清华软院博士研究生我与 vLLM 的缘分,还得从五年前的那个暑假说起。2019 年,我在UC Berkeley的RISELab跟随Michael Jordan教授进行暑期研修。某天,我偶然遇到一位新入学的博士生,厚着脸皮加了他的微信。当时的我怎么也不会想到,这一“社交冒险”会在五年后改变我的人生轨迹。时间快进到 2022 年年底,ChatGPT 横空出世。曾经和我一起玩泥巴的青苹果同学已经成为ChatGPT训练师,而我还在AI顶会与随机分配的审稿人展开“鸡同鸭讲”式的争论。顶会的内
Deepseek来了一波疯狂炸场,把全世界的目光都吸引了过来,这波泼天的流量也是没谁了。年后没多久,因为一些特定的原因,官网的Deepseek基本都变成了这个状态手上刚好有几张算力还算可以的显卡经过一系列折腾终于完成了完整版Deepseek-r1 671B满血版生产级的部署,本来就来详细讲一下。本人水平有限,部署过程中对各种设备、模型、网络等内容的理解有限,还望各位高手指正一、准备工作1.1 模型文件生产级满血版的Deepseek-r1,我们应该直奔他的原版仓库1. huggingfa
说明:本文的任何主观性语句仅代表个人观点。本人才疏学浅,语言通俗可能有不严谨或有误之处,如您对文章内容存疑,欢迎在评论区/私信指出讨论。写文时间:2025年2月15日。一切价格与性价比相关信息以此时为准。deepseek爆火的背后,溯其本源,是这两个关键句:大公无私的开源精神;打破常规的低成本。我们夸它开源,是因为它媲美全球各大公司的闭源模型;我们夸它成本低,绝不是夸它“用的钱少”,不是所谓“仅几百万美金的训练成本”,而是背后研究团队对MoE架构的改良、对注意力机制的改进、对迭代算法的各种优化…
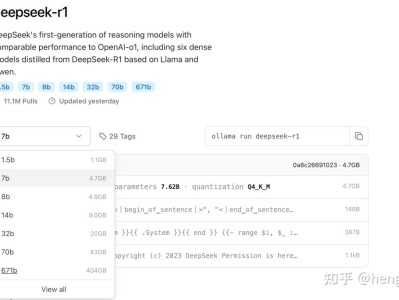
首先介绍下DeepSeek全网使用教程和资料汇总,需要的小伙伴可以自行下载相关教程。DeepSeek全网使用教程和资料汇总DeepSeek-R1 通过其强大的推理能力和灵活的训练机制,已经火爆了整个春节。DeepSeek-R1 是一款高性能 AI 推理模型,旨在通过强化学习技术提升模型在复杂任务场景下的推理能力。本地部署 deepseek-r1 硬件需求要求还是挺高的,特别是满血 671b 参数版本:下表说明了各个版本的特点及适用场景:其中最强悍的 671B 版本部署需要极高的硬件配置
在科技飞速发展的今天,人工智能尤其是大语言模型的发展令人瞩目。DeepSeek R1 作为其中的佼佼者,过年期间更是彻底破圈,受到广泛关注。虽然网络版和 APP 版已经能满足很多人的需求,但对于技术爱好者和追求极致个性化的用户来说,将模型部署到本地,才能真正实现独家定制,让 DeepSeek R1 的深度思考 “以你为主,为你所用”。 大多数人在本地
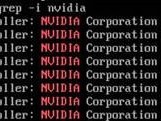
问题描述Nvidia系列GPU(含P100) Linux和Windows驱动安装方式介绍 解决方案1 Redhat server 7.3 驱动安装1. 使用xftp上传驱动到服务器2. 检查GPU卡是否被识别到,运行$ lspci | grep –i nvidia,如下图所示: 3. init 3 切换到文本模式4. &n
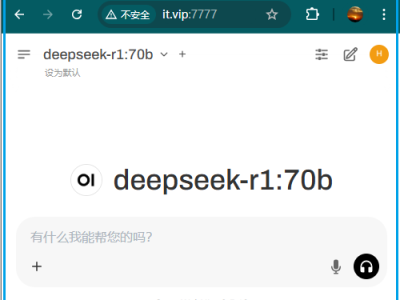
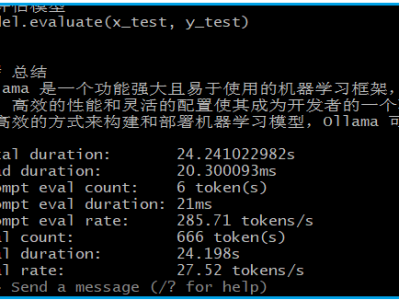
目前 Open WebUI 最便捷的部署方式是通过 docker 部署,一行命令就搞定了:$ docker run -d -p 7777:8080 ghcr.io/open-webui/open-webui相对于 chatbox 、cherry studio 等CS架构,Open WebUI 是基于BS架构的。使用BS架构的好处是服务搭建好后,其他人不用安装软件就可以直接通过浏览器使用。Open WebUI 搭建好后的界面如下:与其他o
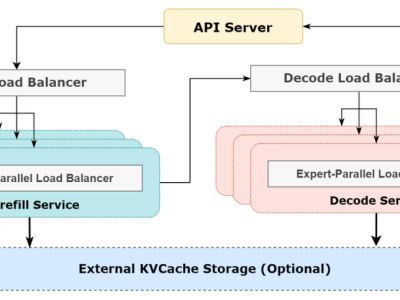
太震撼!DeepSeek用226台H800服务器,日赚409万!大周末的,DeepSeek悄么声放了个大招。他们知乎官号发了一篇雄文,披露了【如何对DeepSeek V3/R1的推理系统进行优化】,文章有2大核心内容↓一、如何通过优化架构,让模型推理获得更大的吞吐和更低的延迟简单概括就是三板斧↓① 大规模跨节点专家并行② 计算-通信重叠优化③ 多级负载均衡策略前两步可以提升吞吐、降低延迟,而第三步用于优化GPU的占用率。DeepSeek在线推理系统架构图二、测算一下:在这种优化架构下,按照目前D
通过昨天的并发测试已经搞清楚了 ollama 的排队运行原理。当多人使用本地部署的 deepseek 时,使用的是先问先答的排队机制。deepseek 回答问题的时间是固定的,不会因为问的人多变得结巴。但同时问的人多,deepseek 会选择一个一个处理,后面的人会处于等待状态。测试过程可以看我昨天的文章:多并发场景 deepseek 答案生成速度会变慢吗?回到主题,本地部署的deepseek能支持多少人同时问问题?如果你家的deepseek是通过ollama来运行的,ollama 自身有排队机
通过 ollama 部署 deepseek 后,如何测试GPU服务器最大能承受的并发数?刚开始通过邀请多人同时在线,通过 open webui 在线聊天的方式测试并发数。因为大家并不是同一时间对 deepseek 提问,问题也不一样,导致生成答案的时间有长有短。如果答案提前生成完,相当于不是并发状态。通过人工方式测试效果不好,于是改用 API 请求方式测试最大并发数。 通过 API 模拟人工方式对 deepseek 发起提问。在服务器空闲状态下进行基准测试:$ollama run&nb
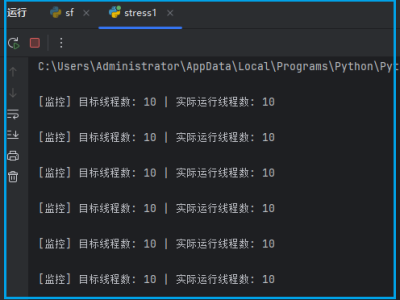
本文主要来测试一下ollama的高并发能力。具体配置如下:一、Ollama默认参数执行我们打开4个窗口,然后分别让DeepSeek “给我讲一个笑话” ,看下不同窗口的答题顺序。通过答题顺序可以看到,在不进行参数设置时,模型是一个一个执行。这样就说明,默认参数下,Ollama并不支持高并发,它会逐个回复我们的请求。二、调整Ollama高并发参数在ollama内,有两个参数与高并发有关分别是:OLLAMA_MAX_LOADED_MODELS:每个模型将同时处理的最大并行请求数,也就是能同时响应几个
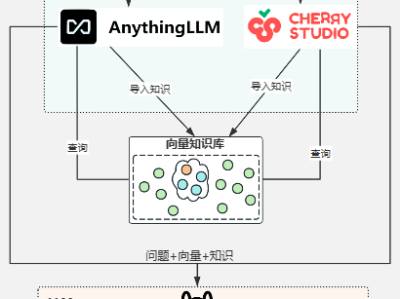
无论是个人还是企业,在数字化时代都面临着海量信息的管理挑战。如何高效整理、存储和检索这些宝贵的数据,成为了提升生产力的关键。今天,我们将分享一个简单易上手的方法——基于 Cherry Studio + DeepSeek R1 模型+嵌入模型,快速搭建属于你或你的企业的知识库!一、什么是 Cherry Studio?Cherry Studio 是一款功能强大且灵活的桌面客户端工具,支持多模型服务,适用于 Windows、Mac 和 Linux 系统。它不仅集成了主流的 LLM 云服务和 AI We
最近,发现越来越多的企业开始跃跃欲试,自建RAG(Retrieval-Augmented Generation)系统,仿佛这是一项简单的任务。毕竟,开源工具到处都是,向量数据库和DeepSeek的组合听起来也不复杂。于是,IT部门信心满满地对领导们说:“我们自己搞,肯定能行!”然而,理想和现实的差距往往让人吃尽苦头。今天,我们就来聊聊,为什么企业自建RAG系统往往会掉进“坑”里,以及为什么多数企业其实更适合购买现成的解决方案。一、个人自建RAG知识库的可行性虽然企业自建RAG系统存在诸多挑战,但
视频教学工具下载Flux1.x 所有内容下载:flux绿色免安装版(含所有官方大模型和工作流、汉化)安装使用第一步 下载上述资料后解压ComfyUI第二步 汉化将 AIGODLIKE-ComfyUI-Translation-main 汉化包解压后复制到 ComfyUI\custom_nodes 目录中第三步 flux模型flux1-dev.safetensorsflux1-dev-fp8.safetensorsflux1-dev-fp8-e4m3fn.safetensorsf