自己去数码之家下载呗...
路由连接数测试软件.zip (63 K) 百度网盘:http://pan.baidu.com/s/1mhKJbO8两台电脑测试路由最大连接数服务端电脑网线接WAN客户端电脑网线接LAN1 设置服务端电脑IP10.168.3.100255.255.2...
还有 1 人发表了评论 加入5316人围观路由连接数测试软件.zip (63 K) 百度网盘:http://pan.baidu.com/s/1mhKJbO8两台电脑测试路由最大连接数服务端电脑网线接WAN客户端电脑网线接LAN1 设置服务端电脑IP10.168.3.100255.255.2...
还有 1 人发表了评论 加入5316人围观支持本网站的,请主动关闭浏览器的广告屏蔽功能再访问本站,谢谢。

这边实际应用中,物料是都要启用批号管理的,那我要设置默认都启用批号管理在哪设置?..每次新建物料的时候忘记勾选启用批号管理,该物料被挂单了就无法再启用批号管理了。
系统中有没有哪个地方可以设置默认启用批号管理的?如果没有,我在bos上扩展物料基础资料,把“启用批号管理”默认勾选是否可行呢
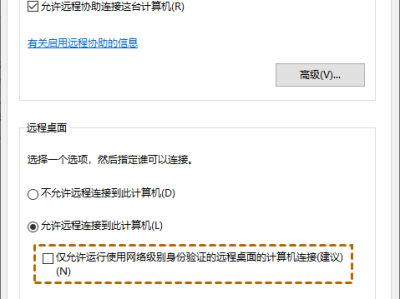
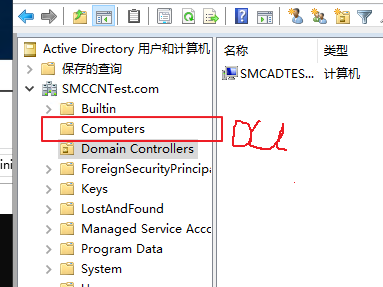
域控制器热备,看到HYPER-V迁移的文章,用这个方法不知是否可行:环境是两台服务器加一台ISCSI存储,要建立一个域服务器,并且可以是热备的,我的想法是做一个MSCS群集,建一个虚拟2008系统,在里面建域来实现,不知是否可行,这样只需管理一个虚拟的系统就行了也实现热备,而用备份域的方法可能较麻烦(没有实施过,只是觉得)。我的结构是这样的:群集用一个域,装在2个节点的其中一个上,然后再在HYPER-V中装2008建一个域,实际用的。如果用备份域这种方式做是否会更好?没有实施过,有没有相关的资料参考一下,非常感谢!
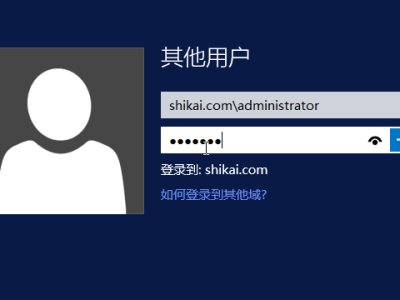
首先,我们登入我们昨天已经加入域的用户(即和之前一样,用(已加入的域名)+(用户名))登入主机(和主域控所在的主机不一样,我这里是登入已加入域的主机)
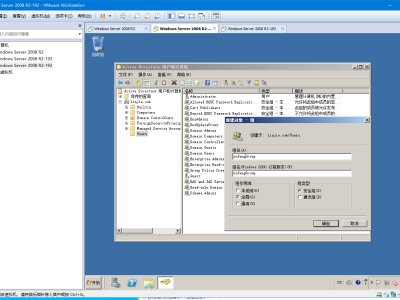
要将域控升级,请问如何检查域控升级前后的状态呢?



您的IP地址是: